
이력 사항
희망 직무 데이터 분석 및 엔지니어
가족관계
| 관계 | 이름 | 나이 |
|---|---|---|
| 부 | 김병수 | 55세 |
| 모 | 곽선아 | 51세 |
| 여동생 | 김은지 | 24세 |
학력
| 학교 | 전공 | 입학 | 졸업 |
|---|---|---|---|
| 컴퓨터공학과 | 2020.03 | 2026.02 | |
| 학점: 3.96 / 4.5 | |||
| 학교 | 전공 | 졸업년월 |
|---|---|---|
| 전북기계공업고등학교 | 로봇자동화과 | 2019.02 |
| 지원중학교 | - | 2016.02 |
| 이리초등학교 | - | 2013.02 |
자격증
| 자격증명 | 발급기관 | 취득일 |
|---|---|---|
| 빅데이터분석기사(필기) | 한국데이터산업진흥원 | 2025.09 |
| ADsP | 한국데이터산업진흥원 | 2025.09 |
| 정보처리기사 | 한국산업인력공단 | 2025.06 |
| ACP 프리미어 프로 | Adobe | 2024.05 |
| 전자기능사 | 한국산업인력공단 | 2018.07 |
| 설비보전기능사 | 한국산업인력공단 | 2018.06 |
| 전산응용기계제도 | 한국산업인력공단 | 2017.12 |
| 전기기능사 | 한국산업인력공단 | 2017.09 |
| 자동화설비기능사 | 한국산업인력공단 | 2016.12 |
수상내역
| 수상명 | 주관기관 | 수상일 |
|---|---|---|
| 빅데이터분석 우수상 | 전주대학교 | 2024.11 |
| 아이디어 우수상 | 전주대학교 | 2025.11 |
| 창의 융합 최우수상 | 전주대학교 | 2025.12 |
병역
육군 | 55사단 | 2022.04 ~ 2023.10 (만기 전역)
보유 기술
기타
기본 기능 활용 | 프로젝트 적용 | 능숙한 활용
프로젝트
프로젝트 요약
P1. Chat JJ : 다국어 지원 스마트 캠퍼스 챗봇
(팀프로젝트, 6명) 2025.03 ~ 2025.06
Ubuntu 기반 데이터 수집/전처리 파이프라인 구축 및 자동화
P2. Northwind 데이터 분석 및 대시보드
(개인 프로젝트) 2025.07 ~ 2025.08
SQL 기반 데이터 추출 및 시각화 대시보드를 통한 인사이트 도출
P3. 공공데이터 기반 대학생 직무 탐색 효과 분석
(팀프로젝트, 3명) 2025.05 ~ 2025.06
SPSS를 활용한 다변량 통계 분석 및 교육 효과성 검증
P4. 텍스트 마이닝 기반 교과목 개발
(개인 프로젝트) 2025.09 ~ 2025.10
에브리타임 크롤링 및 NLP 분석을 통한 수요 기반 커리큘럼 설계
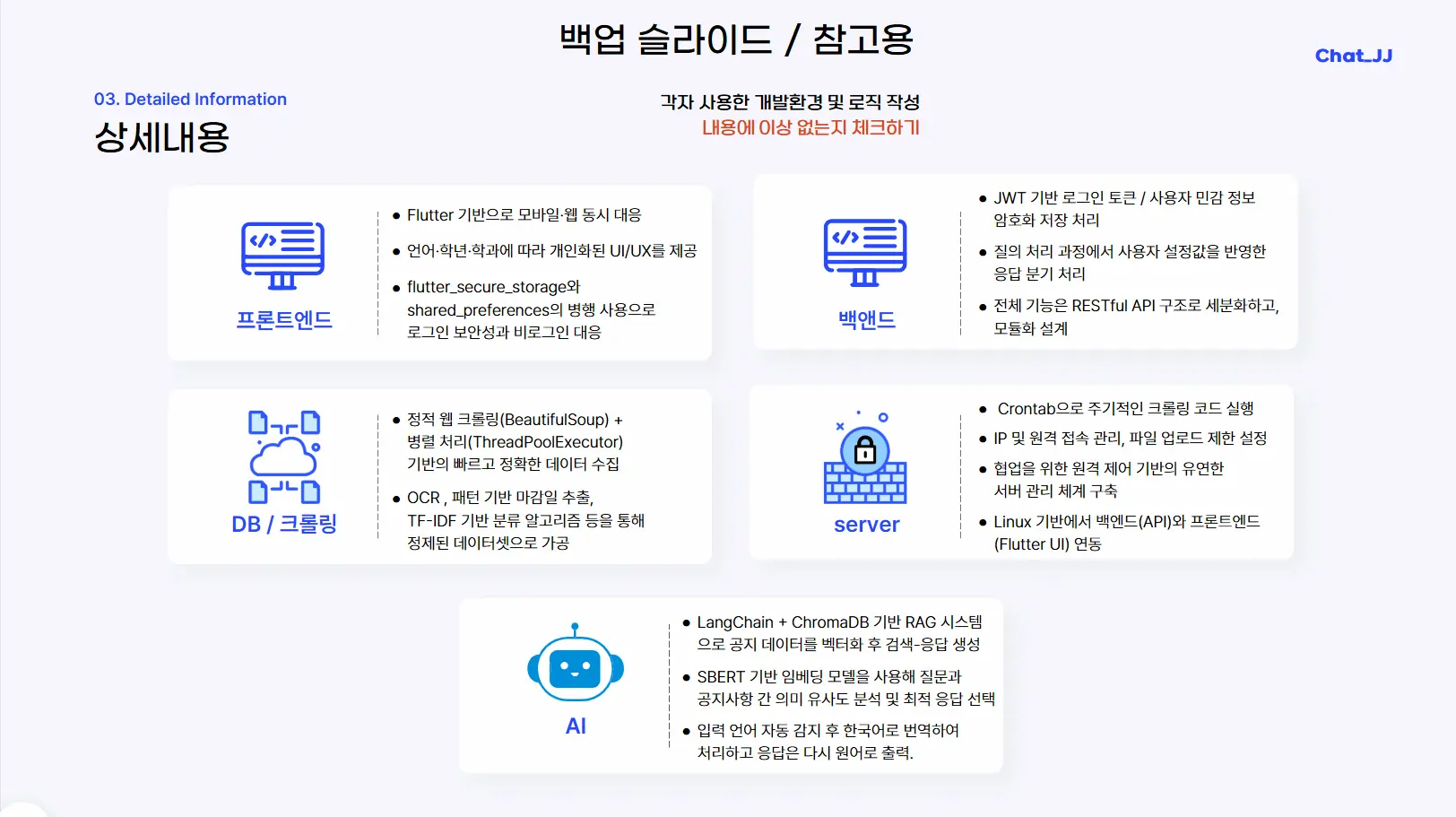
P1. Chat JJ 상세
Tech Stack
Language & Framework: Python, Flask, Spring Boot
Data & AI: Pandas, OpenCV, Tesseract OCR, LangChain, ChromaDB
Infra: Ubuntu Linux, AWS EC2, Crontab
프로젝트 개요
교내에 흩어진 공지사항을 통합 수집하여 학생들에게 맞춤형 정보를 제공하는 챗봇 서비스입니다. 데이터의 수집부터 서비스 적재까지의 전 과정을 자동화된 파이프라인으로 구축하여 정보의 최신성을 확보했습니다.
주요 기능
- 자동화된 데이터 파이프라인: Ubuntu 서버 환경에서 Crontab을 활용한 주기적 크롤링 및 수집 자동화
- 데이터 전처리 및 적재: 이미지(OCR) 및 텍스트 데이터의 전처리 후 Vector DB 자동 적재
- 검색 최적화: 사용자 의도 파악을 위한 RAG 및 TF-IDF 가중치 기반 검색 알고리즘
역할
Ubuntu 기반의 데이터 수집/전처리 파이프라인 구축 및 자동화
기존 챗봇은 수동적인 데이터 관리로 정보 업데이트가 늦었고, 로컬 환경 구동으로 인해 지속적인 서비스 제공에 한계가 있었습니다.
24시간 중단 없는 서비스를 위해 Linux(Ubuntu) 환경으로 서버를 이관하고, 수집(Crawling)-전처리(Preprocessing)-적재(Loading) 과정을 무인 자동화해야 했습니다.
1. Python 크롤러를 서버에 배포하고 Crontab으로 주 2회 자동 수집 스케줄링을 설정했습니다.
2. OpenCV와 Tesseract OCR을 연동하여 이미지 내 텍스트를 추출하고, ChromaDB에 적재하는 통합 파이프라인을 구축했습니다.
3. 방화벽 설정 및 백그라운드 프로세스 관리로 안정적인 서버 환경을 조성했습니다.
수작업 없는 실시간 공지사항 반영 시스템을 완성하였으며, 전처리 파이프라인 도입으로 정보 누락률 0% 달성 및 쿼리 속도 50% 단축을 이뤄냈습니다.
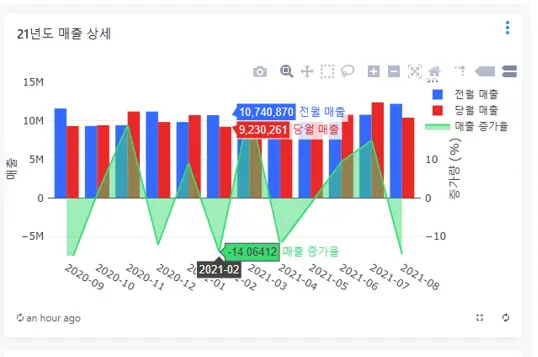
P2. Northwind 분석 상세
Tech Stack
SQL: MySQL (Join, Sub-query, Window Function)
Visualization: Redash, Tableau, Excel
프로젝트 개요
커머스 기업의 매출 증대를 위해 실제 거래 데이터(Northwind)를 분석한 프로젝트입니다. SQL을 활용해 복잡한 데이터를 추출하고, 이를 기반으로 대시보드를 제작하여 비즈니스 인사이트를 시각화했습니다.
주요 기능
- SQL 데이터 핸들링: Join, Sub-query 등을 활용한 정교한 데이터 추출 및 마트 생성
- 데이터 시각화: 월별 매출 추이, 카테고리별 비중 등 분석 결과 시각화
- 비즈니스 대시보드: KPI를 실시간 모니터링 가능한 종합 대시보드 설계
역할
SQL 기반의 데이터 추출 및 시각화 대시보드를 통한 마케팅 인사이트 도출
방대한 커머스 데이터가 DB에 축적되어 있었으나, 이를 비즈니스 전략으로 연결할 직관적인 지표나 시각화 자료가 부재했습니다.
Raw Data에서 유의미한 정보를 추출하기 위해 고도화된 SQL 쿼리를 작성하고, 의사결정 지원을 위한 시각화 대시보드를 구축해야 했습니다.
1. JOIN과 CASE WHEN 구문을 활용해 고객 등급(VIP/New)을 분류하는 등 복잡한 로직을 SQL로 구현했습니다.
2. 추출된 데이터를 Line Chart(매출 추이), Pie Chart(카테고리 비중) 등으로 시각화하여 데이터 패턴을 도출했습니다.
3. 신규 및 충성 고객의 구매 성향을 비교 분석할 수 있는 종합 대시보드를 개발했습니다.
데이터 검증을 통해 신규 고객의 '음료/유제품' 선호도를 발견하고, 이를 바탕으로 이원화된 마케팅 전략(미끼 상품 vs 교차 판매)을 제안했습니다.
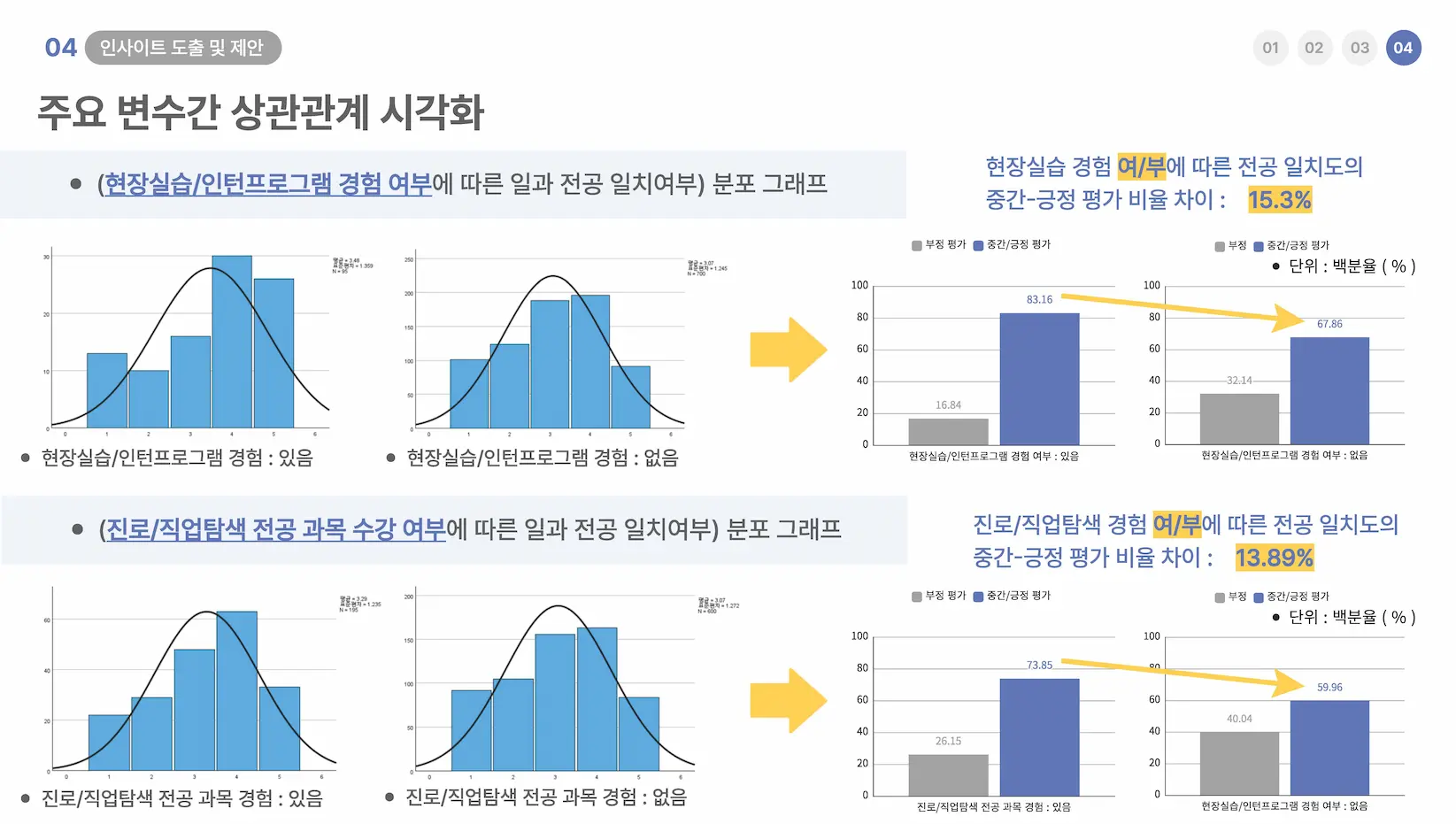
P3. 직무 탐색 효과 분석 상세
Tech Stack
Analysis Tool: SPSS, Excel
Data Source: KEEPII (한국교육고용패널) 7차년도 데이터
프로젝트 개요
교육부의 공공데이터를 활용하여 대학생의 직무 탐색 활동이 실제 취업 성과에 미치는 영향을 분석했습니다. SPSS를 주 도구로 활용해 통계적 가설을 검증하고 심층 분석을 수행했습니다.
주요 기능
- 통계적 데이터 분석: 기술 통계, 상관 분석, 차이 검증 등 전문 분석 수행
- SPSS 활용: 대용량 패널 데이터 핸들링 및 로지스틱 회귀분석 적용
- 가설 검증: 데이터 기반의 논리적 추론을 통한 교육 효과성 입증
역할
SPSS를 활용한 다변량 통계 분석 및 교육 데이터 분석
'전공-직무 불일치' 해결을 위한 효과적인 교육 활동을 파악하기 위해, 추측이 아닌 통계적 근거에 기반한 분석이 필요했습니다.
한국직업능력연구원의 5,800여 명 패널 데이터를 정제하고, '실무 경험' 변수가 '직무 성과'에 미치는 영향을 통계적으로 증명해야 했습니다.
1. SPSS로 결측치 처리 및 변수 재코딩(Re-coding)을 수행하여 데이터 정합성을 확보했습니다.
2. 비모수 검정(Mann-Whitney U)과 순서형 로지스틱 회귀분석을 통해 변수 간 인과관계를 분석했습니다.
3. "현장실습 경험이 전공 일치도와 직업 안정성 인식에 긍정적 영향을 준다"는 결론을 도출했습니다.
정밀한 통계 분석을 통해 교육 정책 수립에 필요한 실증적 근거(통계적 유의성)를 확보하는 성과를 거두었습니다.
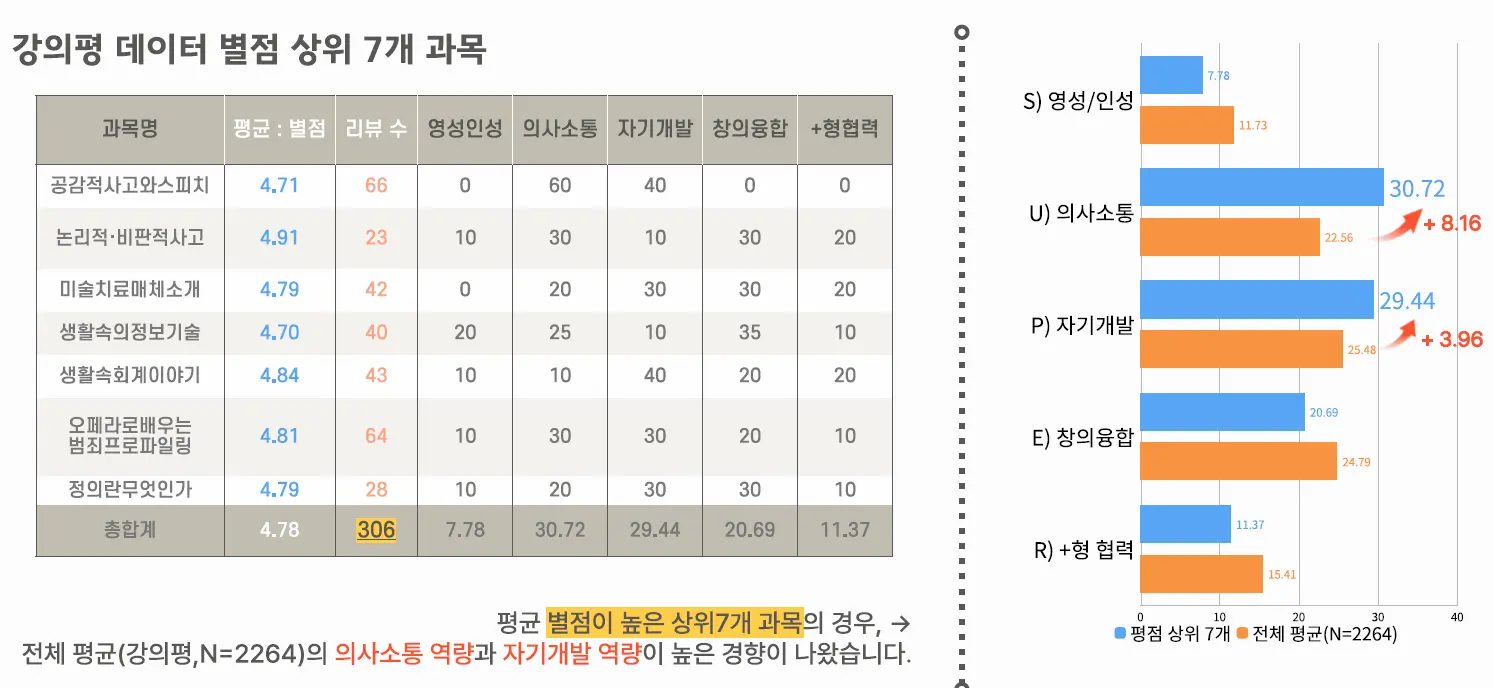
P4. 텍스트 마이닝 교과목 개발 상세
Tech Stack
Language: Python, Excel
Analysis: Web Crawling (Selenium), NLP (KoNLPy), Visualization
프로젝트 개요
교내 커뮤니티(에브리타임)의 강의평을 크롤링하고, 파이썬 자연어 처리(NLP) 기술로 분석하여 학생들의 니즈를 파악했습니다. 이를 Excel로 시각화하여 신규 교과목을 제안한 프로젝트입니다.
주요 기능
- 웹 크롤링: 커뮤니티 강의 평가 데이터 3,016건 자동 수집
- 자연어 처리(NLP): KoNLPy 등을 활용한 형태소 분석 및 핵심 키워드 추출
- 인사이트 시각화: 키워드 빈도수 데이터를 Excel 차트(워드클라우드 등)로 시각화
역할
에브리타임 크롤링 및 NLP 분석을 거쳐 시각화한 수요 기반 커리큘럼 설계
학생들이 진정으로 원하는 교양 수업을 기획하기 위해 주관적 감이 아닌, 학생들의 목소리가 담긴 실제 데이터가 필요했습니다.
수천 건의 텍스트 데이터를 수집(Crawling)하고 분석(NLP)하여, 인기 강좌의 요인을 정량적 지표(Visualization)로 변환해야 했습니다.
1. Python Selenium을 활용해 강의평 3,016건을 자동 수집하는 크롤러를 제작했습니다.
2. 불용어 제거 및 형태소 분석을 통해 '실용성', '부담 없음' 등의 핵심 키워드를 추출했습니다.
3. 추출된 데이터를 Excel 막대그래프와 워드클라우드로 시각화하여 설득력을 높였습니다.
'코딩 없는 실무형 데이터 분석'이라는 구체적 커리큘럼을 도출하고, 공모전에서 그 타당성을 입증했습니다.
자격증
합격증.webp)
빅데이터분석기사(필기)

ADsP

정보처리기사

ACP 프리미어 프로

전자기능사

설비보전기능사

전산응용기계제도

전기기능사

자동화설비기능사
수상내역

빅데이터분석 경진대회 - 우수상

자유교양 아이디어 공모전 - 우수상
-최우수.webp)
창의 융합 경진대회(암호해독) - 최우수상
자기소개서
자기소개
[데이터의 가치를 서비스로 연결하는 실천가]
저는 데이터 분석 역량을 바탕으로, 사용자에게 실질적인 편의를 제공하는 서비스를 만드는 것을 목표로 하고 있습니다. 교내 공지사항 챗봇 프로젝트를 진행할 때 약 700개의 데이터를 직접 크롤링하고 데이터베이스를 구축했지만, 단순히 데이터를 모으는 것만으로는 사용자의 의도를 제대로 파악하는 데 한계가 있다는 점을 알게 됐습니다. 이런 한계를 극복하기 위해, 직접 키워드별로 가중치를 두는 로직을 구현해 검색의 정확도를 높인 경험이 있습니다. 그 당시에는 TF-IDF나 임베딩처럼 더 발전한 자연어 처리 기술을 몰라서 아쉬움이 남았지만, 이 경험 덕분에 데이터가 서비스 안에서 어떤 식으로 활용되어야 하는지 더 깊이 고민하게 됐습니다. 지금은 단순 분석을 넘어서, 웹 서비스 구조와 API 서빙까지 이해하고자 꾸준히 엔지니어링 역량을 키우고 있습니다. 앞으로도 SSAFY에서의 몰입 경험을 바탕으로 기술적인 한계를 극복하고, 데이터의 가치를 높일 수 있는 개발자로 한걸음씩 성장해나가겠습니다.
성격의 장단점 (250자)
[욕심을 계획으로 완성하는 끈기]
제 성격의 장점이자 단점은 성장에 대한 욕심이 많다는 것입니다. 데이터 분석 경진대회와 프로젝트 등 여러 목표를 동시에 이루려다 체력적인 부침을 겪고 결과물의 완성도가 떨어지는 경험을 했습니다. 이를 극복하기 위해 현재는 노션(Notion)을 활용해 세부 일정을 시각화하고 우선순위를 정해 하나씩 완수하는 습관을 들였습니다. 이러한 계획성은 SSAFY의 강도 높은 커리큘럼을 끝까지 완주하는 원동력이 될 것입니다.
봉사활동 (250자)
[경험의 나눔으로 돕는 후배들의 성장]
자유전공학부 신입생 멘토링 활동에 참여하면서 나눔의 가치를 몸소 느꼈습니다. 전공을 선택할 때 실패를 겪고 전과했던 제 경험을 토대로, 진로에 대해 고민하는 후배들에게 현실적인 조언과 학교생활 팁을 전해주었습니다. 멘티들이 제 이야기를 듣고 자신의 적성을 발견하며 점차 학교생활에 적응해 가는 모습을 볼 때마다, 제 경험이 누군가에게 도움이 된다는 사실에 큰 보람을 느꼈습니다. 앞으로도 동료들과 함께 배우고 성장하며, 지식을 나누는 개발자가 되고자 합니다.
지원 동기 및 입사 후 포부 (500자)
[금융의 문턱을 낮추는 챗봇 서비스 구현]
최근 살던 전세집이 경매에 넘어가면서 금융 관련 절차와 각종 서류를 준비하는 데 정말 많은 어려움을 겪었습니다. 이 일을 계기로, 누구나 복잡한 금융 서비스를 좀 더 쉽고 편하게 이용할 수 있으면 좋겠다는 생각이 들었고, 그래서 ‘은행 대출 업무 챗봇’을 직접 만들어보고 싶다는 목표가 생겼습니다. 제가 SSAFY에 지원한 이유도 이런 아이디어를 실제로 구현할 실력을 키우고 싶어서입니다. 특히 데이터 트랙에서 현업 수준의 대용량 데이터를 직접 다뤄보고, 분류 예측 모델링이나 자연어 처리 기법을 깊이 있게 배우고 싶습니다. 그리고 5대 시중은행과 연계한 프로젝트를 경험하면서 실제 금융 데이터를 다루고, 개인별 상황에 맞춘 대출 상담과 서류 안내가 가능한 챗봇 서비스를 직접 만들어보고 싶습니다. 이런 경험을 통해 진짜 현장에서 쓸 수 있는, 완성도 높은 결과물을 내는 것이 저의 목표입니다.